WTF - Wikipedia Traffic Forecasting
21 Sep 2017TL;DR
I participated in my first Kaggle competition, the Web Traffic Time Series Forecasting competition, where I attempted to predict daily visits to Wikipedia pages 2 months in advance. I’m currently at 74th out of 1095. It occupied more time and I got worse results than what I expected. Overall it was a fun way to learn quite a few new things.
The Competition
Goal
Predict the daily page views for 145 000 different wikipedia pages. These included pages from different languages and some were even wikimedia links.
Data & Timeline
The training data consisted of the page views of each page since the 1st of July 2015. During the first phase of the competition there was data available until the end of 2016 and we had to predict for the first 60 days of 2017. On the beginning of September the data up until the end of August was released. And the final data set with the data until the 10th of September was released one day and half before the final submission.
The decision to reduce the time between the final dataset release and the submission deadline was made during the competition and surprised many of the contestants. I believe this small timeframe to train and generate the final submission will affect negatively the more complex models, which require more time to train.
I found these two Kaggle kernels very useful to understand the characteristics of the dataset:
Evaluation
The models will be evaluated on the prediction of the daily page views for all pages on the 62 days between the 13th of September and the 13th of November. The cost function is the SMAPE (Symmetric mean absolute percentage error) which disregards outliers. (Here is a very nice kaggle kernel analyzing the SMAPE.)
My Approach
I wanted to play around with simple models and with some ideas I had of how to augment the available data, so I ended up not trying any traditional Machine Learning approach such as neural networks or xgboost.
Data Augmentation
As each time series corresponds to a wikipedia page my first idea was to scrape each of those pages for additional data. With BeautifulSoup and Requests libraries I created a simple script to fetch the text content of each wikipedia page. The complete code is available on this kernel, but this is the main piece:
def fetch_wikipedia_text_content(row):
"""Fetch the all text data of a given page"""
try:
r = requests.get(row['URL'])
# Sleep for 100 ms so that we don't use too
# many Wikipedia resources
time.sleep(SLEEP_TIME_S)
to_return = [x.get_text() for x in
BeautifulSoup(
r.content, "html.parser"
).find(id="mw-content-text"
).find_all('p')
]
except:
to_return = [""]
return to_returnI had many ideas on how to use this data to improve my results, however I ended up only having time to test of them.
Dates Of Interest
One thing that intrigued me was wether I would be able to predict the spikes in the visits of a given page. I hypothesised that most Wikipedia pages would contain on the text content the dates where there would be a spike. For instance for celebrities I though the birth and death dates would coincide with a increase in the amount of visits surrounding those dates annually.
To test this I extracted from the text content all the mentioned dates, for this I used the datefinder python library which works ok, but mostly only for english text. So I got in the end around 9500 english pages with dates that coincide with my training data period. I then calculated how the median visits around those dates diverged from the page median and got the following plot:
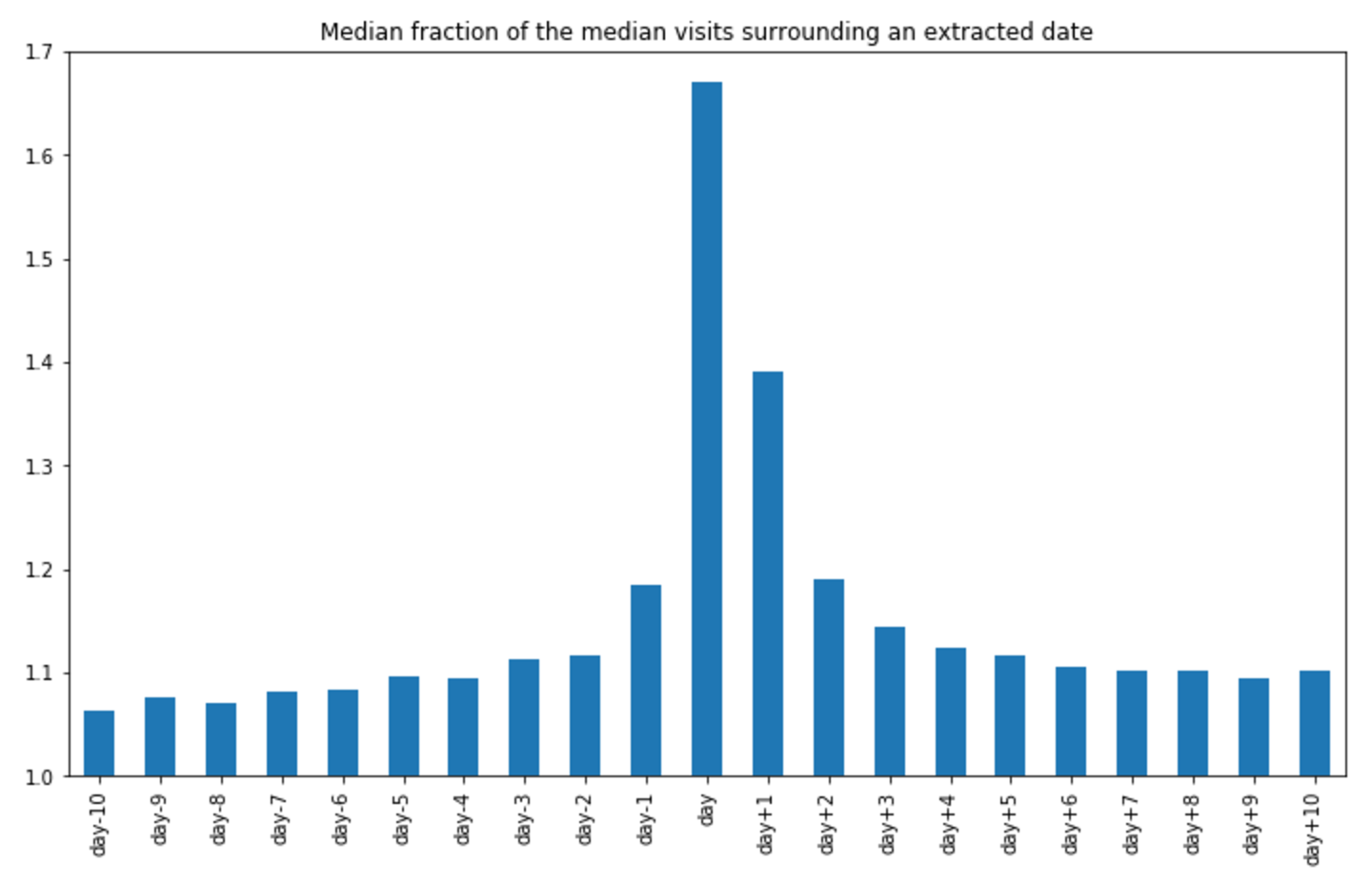
There is a clear effect on the visits on the days surrounding these dates. As such I decided to modify my models to increase the predicted number of visits on the days surrounding the dates extracted on the same proportion that this plot identifies.
This lead to a small improvement on my SMAPE score on the pages with dates, but as I only had dates for 9500 pages it had virtually no impact on the overall score.
Last Day Improvements
On 12th of September with the data available until the 10th I decided to try and fetch the daily visits from the Wikipedia API for all the days in September and fill NaN values. This gave me an extra day of training data and some more data points for the previous days. The API calls were done with a simple script, inspired from this kernel.
With some modifications to better encode the page’s names:
def get_views(web_info, dates=['20170911']):
"""Fetch the daily page views for a wikimedia page"""
page = web_info[0]
web_info = web_info[1:]
url = ('https://wikimedia.org/api/rest_v1/metrics/' +
'pageviews/per-article/{0}/{1}/{2}/{3}/daily/' +
'{4}/{5}').format(
web_info[1], web_info[2], web_info[3],
urllib.parse.quote(web_info[0], safe=':'),
dates[0], dates[-1])
res = np.array([np.nan for i in dates])
try:
url = urllib.request.urlopen(url)
api_res = json.loads(url.read().decode())['items']
except:
print('Failed for: ', page, ' quoted = ',
urllib.parse.quote(web_info[0], safe=':'))
return res
for i in api_res:
timestamp = i['timestamp'][0:-2]
res[dates.index(timestamp)] = i['views']
return resThe Result
Final results aren’t available yet, as the models are evaluated on future data the scores will only be available on the 15th of November. Currently I’m at 74th out of 1095 teams that participated with a 39.72 SMAPE score. The best score is of 34.79.
Tools
I worked on Jupyter notebooks with Python 3 which led to my code being quite messy, I will share it after I clean it up.
As this was a time series problem and as I played mostly with median based models my most useful library was Pandas. The different ways to merge different sources of data into a single dataframe proved extremely valuable. Besides the already mentioned datefinder, BeautifulSoup and Requests libraries were also used.